
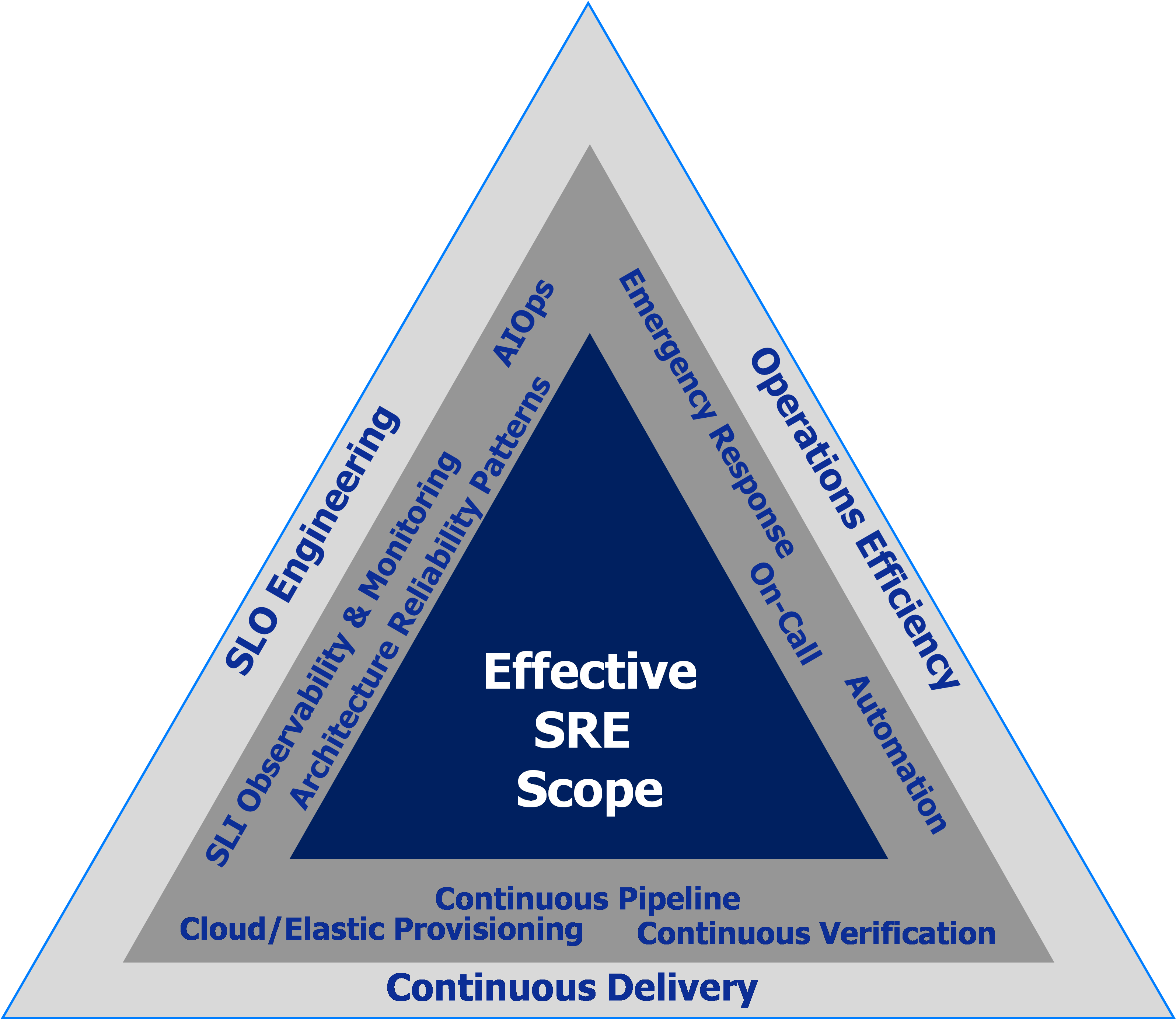
As part of our democratised approach for companies to adopt SRE, we have introduced in a previous blogpost our “Effective SRE” challenge triangle (see below). We then mentioned “SLO Engineering” without exploring it in further details and without describing its related key activities. In this blog post, we will provide you an overview of SLO Engineering as one of the key responsibilities of the SRE role.
We will focus especially on the first step dedicated to the SLO/SLI Specification and Reliability Requirements Analysis by introducing the terminology of SLI and SLO. We will also provide you with good practice insight on how to define these metrics and will introduce the concept of error budget.
We will further deep dive into details of the other activities and steps related to the “SLO Engineering” approach in a subsequent post.
SLO Engineering
Applying a systematic engineering approach to Service Level Objectives (SLO) is key for the successful adoption of Site Reliability Engineering (SRE), because SLOs themselves allow the teams to effectively manage the user services they are responsible for (see 1).
At Digital Architects Zurich we define “SLO Engineering” as the set of activities required to pro-actively manage the SLO throughout the whole service/application life cycle from requirement specifications through architecture, development, testing until operations.
SLO Engineering consists therefore mainly of:
- SLO/SLI Specification based on Reliability Requirements Analysis (RRA), considering on one hand the requirements expressed by the business and on the other hand the usage patterns analysis of any existing production logs or other monitoring sources
- Architecture Reliability Patterns: ensure that reliability requirements specified in terms of SLOs, are part of your non-functional requirements definition. Reliability requirements need to be taken into account when building and designing the architecture. This can be done in different ways such as:
- A risk-based analysis to drive the evaluation and selection of architecture and design patterns (such as load balancing, caching, asynchronous processing, sharding, geographic isolation, etc… ) to mitigate the risks.
- Apply architecture and design patterns enabling an incremental release strategy such as canary or blue-green release approach. Also, rollback automation to reduce reliability risks related to application changes.
- Furthermore, you need to adress the measurability of the SLO by breaking it down into well-defined SLIs and other contributing SLIs and metrics as a part of the reliability architecture blueprint. These need to be translated into observability and alerting requirements resp. stories.
You should consider adding them to the developer’s backlog in order to implement them in code (“Monitoring as a Code”), or adding them as requirements to the SLO/SLI Measurement & Observability Platform the SRE need to build and operate. - SLO/SLI Measurement & Observability Platform: ensure that SLO/SLI as well as the observability data introduced above are collected. Choose e.g. OpenTelemetry frameworks, streaming technologies and Big Data platforms adapted to the context.
- SLO/SLI or Site Reliability Testing: Before moving to production, you need to test and validate the SLO requirements and the observability stories. Therefore, application reliability test scenarios with the objective to validate both SLOs and Observability stories will be designed and executed usually under realistic load, stress and disaster test scenarios.
- Continuous Delivery (CD) pipeline incl. Continuous Verification: design and build the CD pipeline while considering the implementation of Continuous Verification of automated test execution and/or of SLO/SLIs exposed by the measurement and observability platform.
- SLO/SLI Management in Operations with Domain-agnostic AIOps (Artificial Intelligence for IT Operations) is the approach combining the use of Big Data, machine learning and other analytics techniques to manage the SLO efficiently from end-to-end in a high speed delivery and cloud-able operations. This allows real-time collection and ingestion of the metrics and events related to the ephemeral micro-services and containers running in the cloud, acting quicker to incidents and changing systems because of AIOps’ capabilities (such as instant anomaly detection, alerting, prediction, root-cause identification and dynamic insights/visualisation…)
Some Terminology
Before we dive into the details of how to come up with practical and efficient indicators and objectives, we need to establish a few terms:
- Reliability has been an important quality attribute for systems and software since a long time (see 3 and 4). The standard definition (see 5) is:
“ability of a system or component to function under stated conditions for a specified period of time”
- A Service Level Indicator (SLI) is a metric that has been chosen to measure an aspect of the reliability of a service. A possible definition comes from Google (see 6):
“A quantifiable measure of the reliability of the service”
or slightly different: “A measurable analogy for user happiness”
Typically, an SLI is established as the ratio between good events and valid events which allows to represent each indicator as percentage.
- A Service Level Objective (SLO) is built on one or more Service Level Indicators and, according to Google (see 6), is defined to:
“Set a reliability target for an SLI over a period of time”
Typically, an SLO’s reliability target will be a number close to 100%, for example 99.9% (or even more “nines”). And even though SLOs are internal goals for services, being out of the SLO must have consequences for the development and SRE teams, we will get to this further below.
- Service Level Agreements (SLA) are external facing contracts that describe the minimal level of service that is provided to users and comes with penalties in case the SLA is not met over a defined period of time. An SLA is built from SLOs in the case of Site Reliability Engineering, however typically the SRE team is not directly involved in the definition of SLAs and this is left to the business and product owners. As best practice, SLOs are much tighter than the corresponding SLA to allow for reaction time and prioritisation of activities before customers get unhappy (i.e. the SLA is breached).
- Error Budget: because users typically cannot tell the difference between a service that is 100% available and 99.9% available (nice quote from Ben Treynor (see 7): ”100% is the wrong reliability target for basically everything”), we use this perception gap and define the error budget as (see 8):
“acceptable level of failure for a service over some period of time”
If this by the users’ accepted failure time is not consumed by service downtime, we can actively spend this time for activities, and we will describe this in more detail below. The agreement on active use of the time difference is a key principle for SRE adoption. The calculation of the allowed error budget is easy: it is 1 minus the SLO of the service, typically calculated over a rolling period of a month, in above example therefore 0.1%.
Note that it depends very much on the service type if maintenance windows deplete the error budget or not (see 9). In any case however and due to the impact on reliability engineering, it needs to be a conscious decision by product and service owners.
How to set good SLOs and SLIs?
We at Digital Architects Zurich believe in the fact that “A good SLO captures the state of availability and performance of a system so that, if just met, the users are happy with the system” (see 6). This may sound simpler than it really is, as there are serious challenges to overcome.
- “users” are not a homogenous group of people and might have very different expectations or need for change (i.e. spend of error budget)
- “just meeting” the SLO is difficult, because you also do not want to be “too reliable” and thus waste your error budget without getting extra happiness from the users or
- even create the expectation that the service always works which will result in more complaints if you start using (or needing) the error budget
With this in mind, we create our definitions according to the following best practice, high-level approach inspired by Google’s Art of SLOs and Elisa Binette’s Best Practices for Setting SLOs and SLIs for modern complex systems.
- Reliability Requirements Analysis (RRA) to identify the reliability critical use cases
You can use different approaches to identify the user journeys that are critical to the system: conduct user interviews, analyse production monitoring data or log files for usage patterns, and combine those inputs with non-functional aspects of the system. By using reliability requirements analysis to identify non-functional expectations, you will understand which journeys are business-critical, high frequent or have a high resource impact. Always ensure you understand what is happening in the journey, visible for the user as well as internally in the system (i.e. as sequence diagram). Having and architectural/infrastructure view of the system and its boundaries is highly important to later identify gaps in your SLI definition.
Example of reliability critical use cases: “Load user’s bank account statement page”
- Choose the appropriate SLI type for each reliability critical use case
A possible approach to come up with SLIs for specific types of requests can be found in Google’s “SLI Menu” (see figure 1) where we differentiate three different types of journeys: request/response, data processing and storage. Each of those types comes with different dimensions for good SLIs. We pick multiple indicators for each user journey.
Example SLI: “The bank account statement page should load successfully” (availability) or “The bank account statement page loading time” (latency)

- Specify SLI and implementation (measurement strategy)
Find a measurable implementation for the detailed specification of the SLI. Make sure that the specification includes an event, success criteria and where/how it is measured.
The SLI is best expressed as an equation between good events that fulfil the success criteria and all valid events (e.g. you might want to exclude HTTP 500 errors as invalid events):

Note that, typically SLIs are not infrastructure metrics (CPU, load, memory usage, network bandwidth), but should rather be directly connected to user happiness. Of course, you should still be collecting infrastructure metrics to be able to debug and identify root-cause of an outage, feed into AIOps to detect and correlate anomalies in order to be able to prevent and quickly understand SLI degradation.
Moreover, it is key to have a detailed understanding of what monitoring perimeter is included in the measurement method you choose. For example, some might exclude requests that failed on the network layer, others might only show approximate or delayed timing. To ensure consistent and sustainable metric collection, it is advisable to leverage “Monitoring as a Code” or similar approaches for observability / monitoring / instrumentation configuration.
Example SLI implementation: “Proportion of account statement page requests (event) that were served in <1250ms (success criterion), as exposed by the measurement and observability platform (measured where/how)”
- SLI failure & boundary analysis
Once the SLI is specified, you walk through your system infrastructure and validate that all failures with impact to the related critical use case are captured. Leave out failures from your SLI if they are out of your control. However, make sure you still establish visibility into these boundaries through monitoring and AIOps to allow efficient support.
- Set SLO based on past performance and/or business need
The last step is to create the SLO based on one or multiple SLIs by adding a target and a measurement window. Ensure that the SLO is achievable reviewing past performance data (monitoring tooling, log files) and make sure you keep the original business need in mind by setting the target where the SLI starts to create unhappy users.
Example SLO: “99% (target) of account statement page requests served in <1250ms in previous 28d (measurement window)”
- Document and share your SLI/SLO specifications/contracts & design
Ensure transparency of what has been agreed as targets and keep in mind to re-iterate and validate the indicators and objectives regularly to ensure that they are adjusted in case of changed business priorities or system architecture.
If you follow this approach/formula, you will be able to create the initial set of SLI and SLO for your service that can be used as basis for the next step of error budget spending.
What about my service dependencies?
It is key to remember that a typical service is relying on other services to function. As some of those dependencies might be critical for your service, you will have to consider the SLO offered by those for the calculation of realistic SLO targets.
To understand dependencies, SRE will have to conduct reliability requirements analysis and subsequently apply architecture reliability patterns to improve their own service’s reliability.
In addition, it is important for your monitoring systems to provide visibility not only into your SLI/SLO status, but also include metrics from key dependency services. This will allow the SRE team to more quickly identify if a violation stems from your own service or is it “just” a dependency.
Understanding your service dependencies is quite important in order to come up with the right strategies for application reliability engineering, especially in cases where depending services keep “spending your error budget” or impacting your SLO.
What to use the Error Budget for?
According to the definition stated before, you should use the error budget to balance reliability and the pace of innovation, typical activities include :
- releasing new features
- expected system changes
- inevitable failure in hardware, networks, etc.
- planned downtime
- risky experiments
Some of these activities can be planned for, however some might just occur through unexpected failures. That is why it is additionally important to take conscious decisions about spending the remaining of the error budget.
While you might want to use fixed, e.g. quarterly, periods for SLO reporting, it is recommended to calculate the error budget of a rolling time window. In that way, it is possible to manage priorities for above activities in a constant flow.
As product owner, product engineering and SRE have agreed to the SLOs it is clear to everyone that if you run out of error budget for a calculation period, change for that specific service has to wait until the objective is back to green again (or alternatively, change is only allowed for stabilisation tasks that all team members focus on, see 11). A key principle for this to succeed is the authority of the SRE team to say “no” in those cases.
We will deep-dive into the topic of how to balance delivery velocity and stability through error budget and error budget policies in a later post.
Please let us know if you have comments or would like to understand how Digital Architects Zurich can help you build the Digital Highway for Software Delivery or provide training and engineering power for your team to effectively set-up Site Reliability Engineering, Service Level Objectives (SLO) or Service Level Indicators (SLI) for your business.
Foot notes/References:
- Site Reliability Engineering Workbook, Chapter 3 – SLO Engineering Case Studies (McCormack and Bonnell, 2018) https://landing.google.com/sre/workbook/chapters/slo-engineering-case-studies/
- Effective SRE (Digital Architects Zurich, 2020)
https://www.swiss-digital-network.ch/effective-sre-how-to-democratize-and-apply-
site-reliability-engineering-in-your-organisation/ - Software Reliability (ScienceDirect, 2020)
https://www.sciencedirect.com/topics/computer-science/software-reliability - List of system quality attributes (Wikipedia, 2020)
https://en.m.wikipedia.org/wiki/List_of_system_quality_attributes - IEEE Standard Computer Dictionary: A Compilation of IEEE Standard Computer Glossaries (IEEE, 1991)
- The Art of SLOs (Google, 2020), http://cre.page.link/art-of-slos
- Interview with Ben Treynor, VP of Engineering at Google, https://landing.google.com/sre/interview/ben-treynor-sloss/
- The Calculus of Service Availability (Ben Treynor, Mike Dahlin, Vivek Rau, Betsy Beyer, 2017), https://queue.acm.org/detail.cfm?id=3096459
- How maintenance windows affect your error budget — SRE tips
(Jesus Climent, Google, 2020)
https://cloud.google.com/blog/products/management-tools/sre-error-budgets-and-maintenance-windows - Best Practices for Setting SLOs and SLIs For Modern, Complex Systems (Elisa Binette, New Relic, 2018)
https://blog.newrelic.com/engineering/best-practices-for-setting-slos-and-slis-for-modern-complex-systems/ - Monitoring Services like an SRE in OpenShift ServiceMesh (Raffaele Spazzoli, RedHat, 2020)
https://www.openshift.com/blog/monitoring-services-like-an-sre-in-openshift-servicemesh